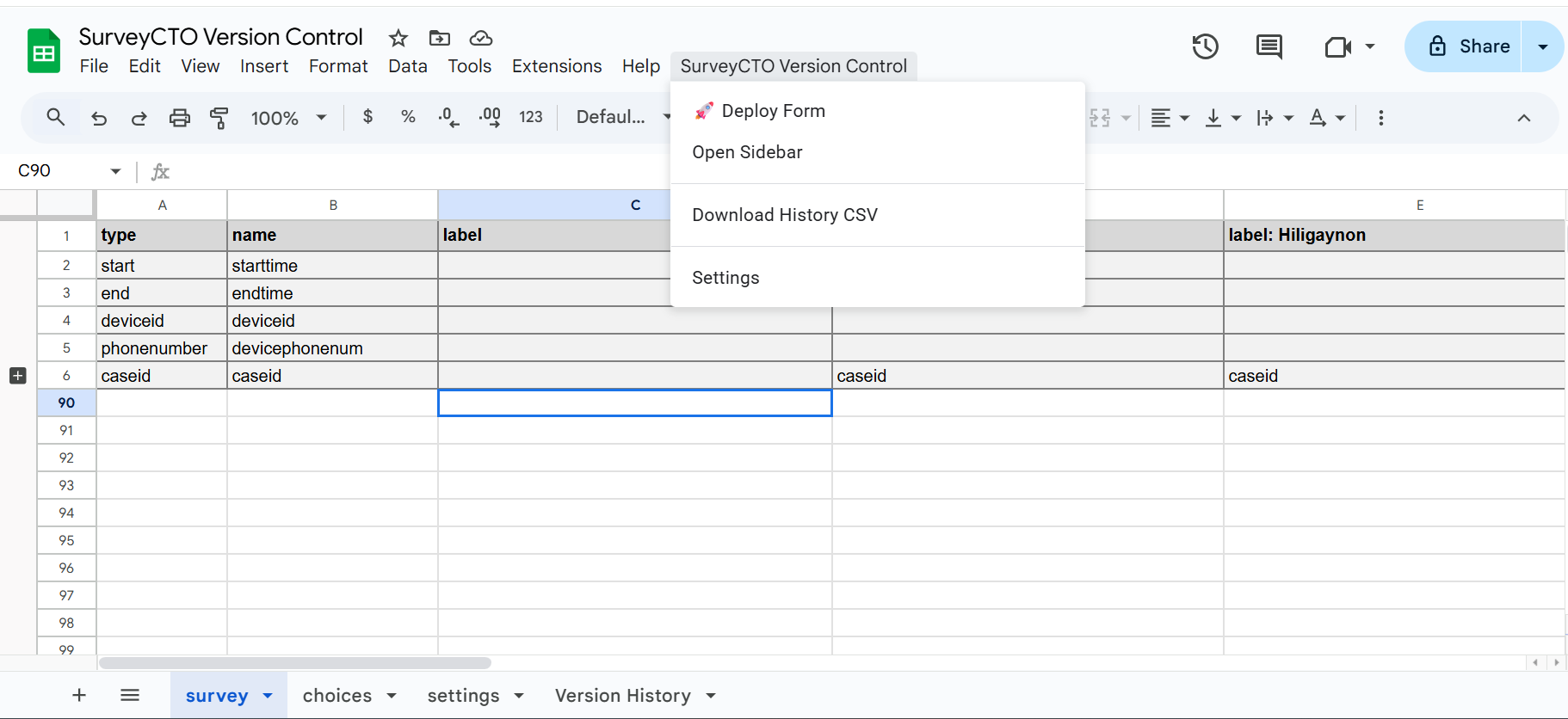
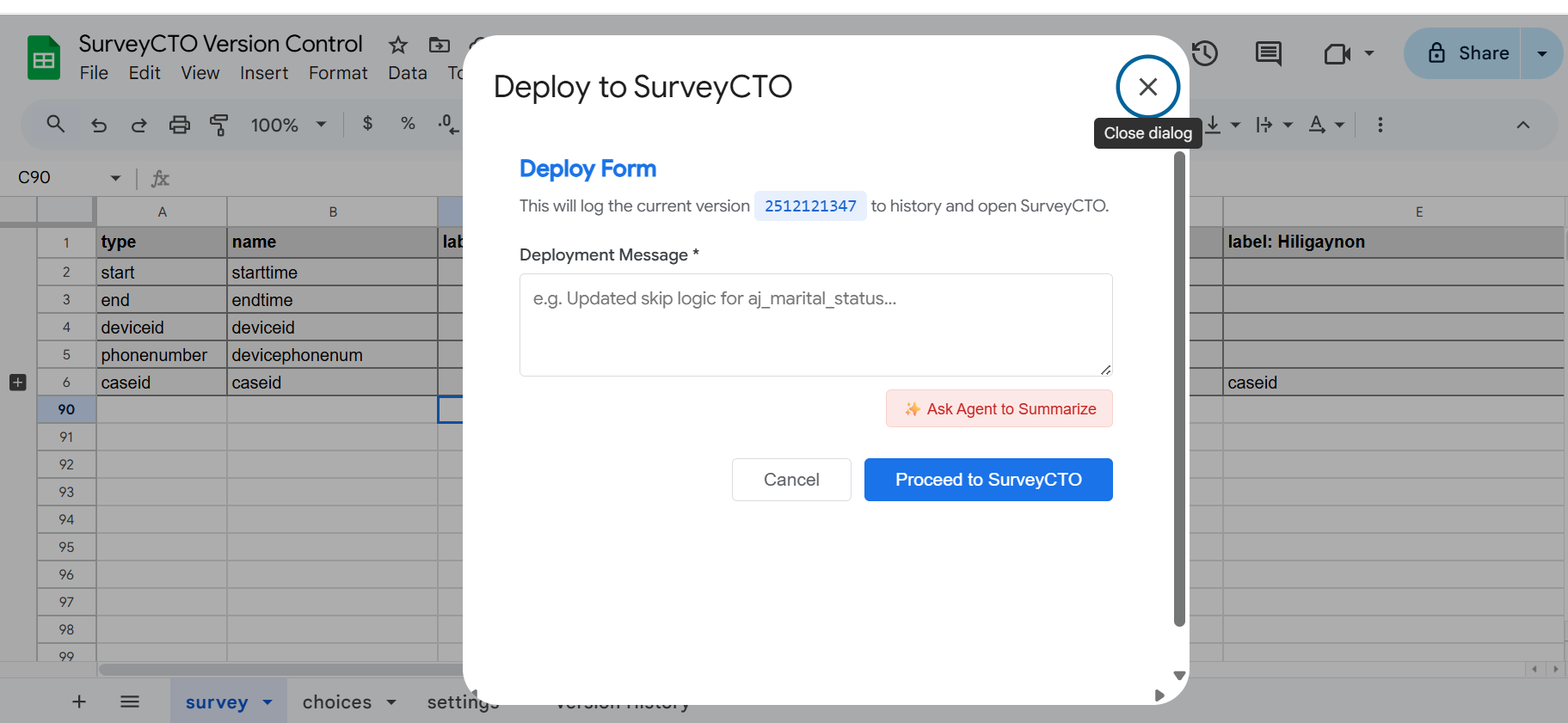
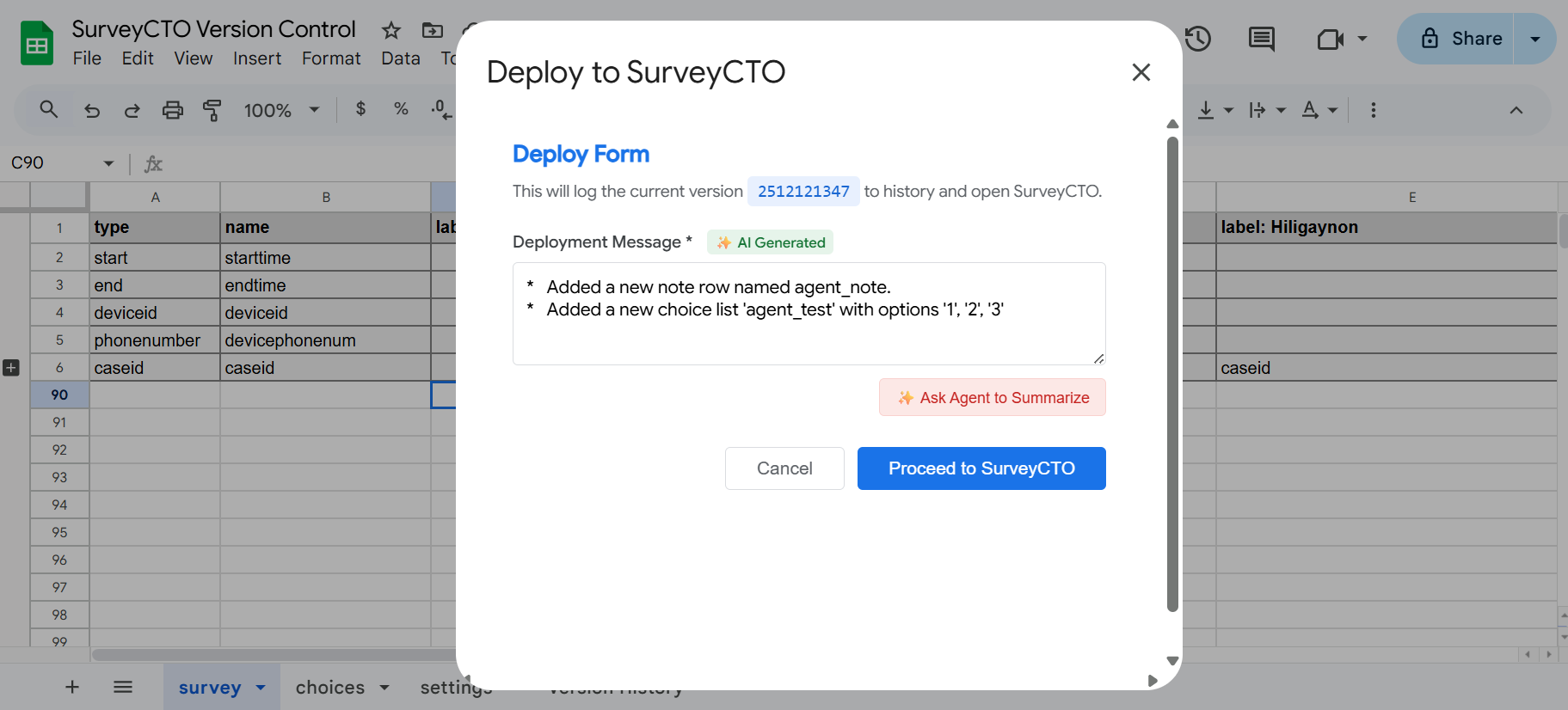
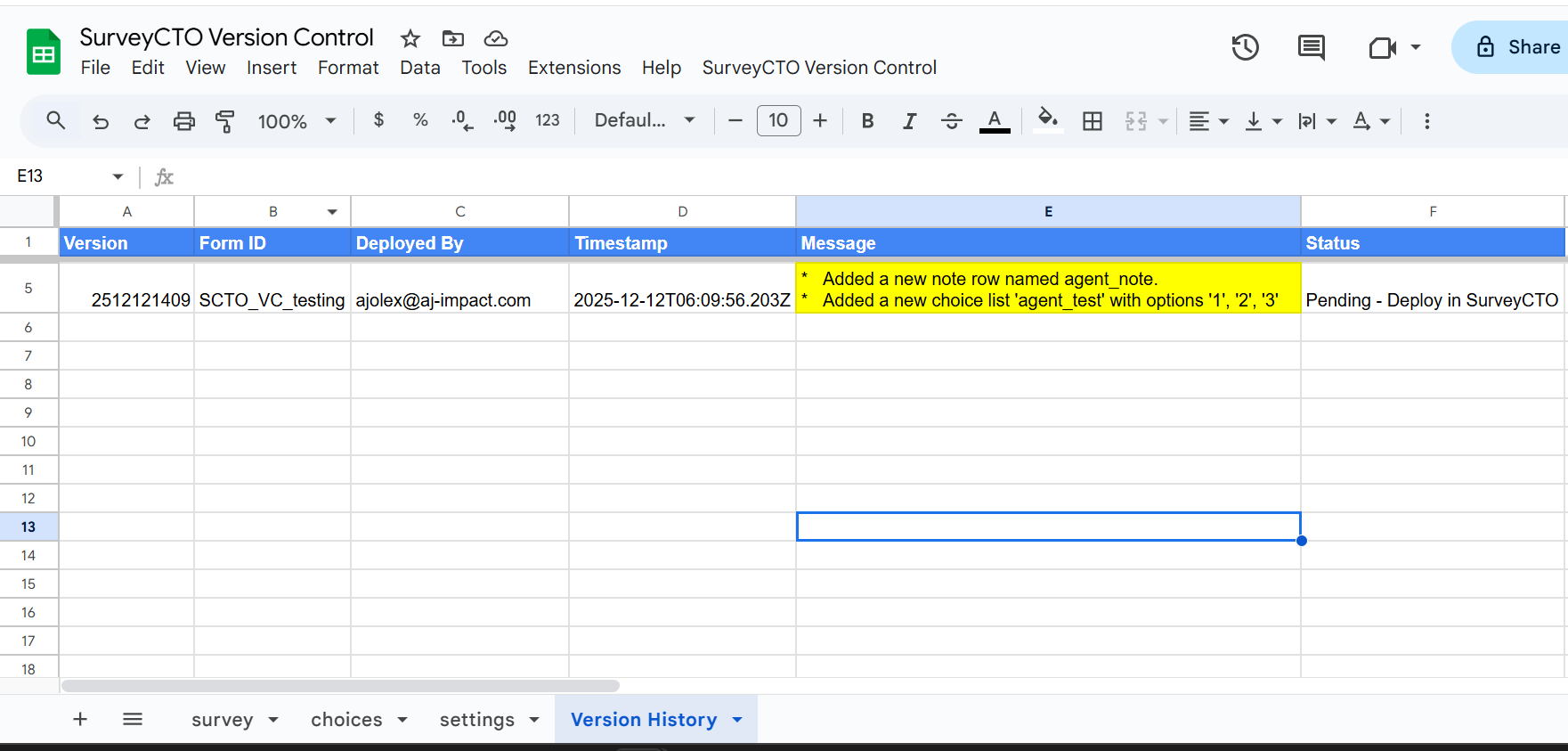
The Future of Research is Human-Powered AI: Introducing DERA
The future of research isn’t AI replacing human expertise—it’s AI amplifying it.
By Aubrey Jolex | December 15, 2025
We’re at an inflection point. AI is fundamentally changing how we research, learn, and solve problems in development economics. Yet the skepticism persists—and rightfully so. We’ve all seen the disclaimers: “ChatGPT can make mistakes, so double-check it.” We’ve all experienced AI confidently providing plausible-sounding answers to questions it has no business answering.
But here’s what I’ve learned: dismissing AI entirely is just as risky as trusting it blindly.
The truth? The future of research isn’t AI replacing human expertise—it’s AI amplifying
it. This is what researchers call Human-AI collaboration, and it’s transformative when
done right.
The Problem: Lost Hours in Literature Labyrinths
Let me paint a familiar picture. You’re a development economist planning a study on cash transfers. You need to understand what’s already known. So you start searching:
- NBER working papers
- World Bank policy research
- J-PAL and IPA evaluations
- Cross-referenced journal articles
- Grey literature and policy briefs
By the time you’ve synthesized findings across these fragmented sources, you’ve burned 40-60 hours of research time. And you haven’t even started your actual analysis yet.
Literature review—the foundation of rigorous research—has become a bottleneck. We’re losing time on the searching when we should be spending it on the thinking.
Introducing DERA: Intelligence With Guardrails
DERA (Development Economics Research Assistant) is designed with this exact challenge in mind. It’s an AI-powered platform that combines semantic search with Retrieval-Augmented Generation (RAG) to revolutionize how we discover, access, and synthesize research in development economics.
But here’s the key: DERA isn’t here to replace your judgment. It’s here to amplify it.
The DERA interface
simplifies research discovery.
Five Capabilities Built for Human-AI Collaboration
🧠 Semantic Search Engine
Instead of keyword hunting, ask questions in natural language: “What’s the impact of
microfinance on household savings in sub-Saharan Africa?” DERA understands meaning, not just keywords. It finds papers you’d never stumble upon in a traditional search, reducing research time while improving comprehensiveness.
🏷️ Intelligent Categorization
Papers are organized hierarchically using JEL codes mapped to development economics themes. Browse strategically from broad categories (Poverty & Social Protection) to specific topics (Conditional vs. Unconditional Cash Transfers). Structure replaces chaos.
💬 RAG-Powered Research Assistant
Ask your research questions in plain English: “What’s the typical effect size for conditional cash transfers on school enrollment?” The platform retrieves relevant papers and synthesizes findings in context. You get evidence-backed answers—but you always see the sources, letting you verify, challenge, and refine.
🔬 RCT-Focused Evidence Browser
For those prioritizing causal evidence, a dedicated module indexes randomized controlled trials with rich metadata: intervention types, geographic regions, sample sizes, power calculations, and links to replication data. It’s discovery with rigor built in.
📊 Automated Meta-Analysis Engine
Imagine this: the platform automatically extracts coefficients, confidence intervals, and sample sizes from research papers, then visualizes effect sizes in forest plots. It identifies heterogeneity (how effects vary across contexts), all while flagging uncertainty and inviting human verification. You review, validate, and refine—not starting from scratch.
Seamlessly browsing
research evidence.
The Human-AI Contract
Notice what DERA doesn’t do: it doesn’t hand you answers carved in stone. Every feature is designed for verification, refinement, and human judgment. You’re not trusting AI to do your thinking—you’re using it to handle the grunt work so you can think better.
The Hybrid Model
- AI finds the papers; you assess their quality
- AI synthesizes findings; you contextualize and challenge them
- AI extracts numbers; you verify and interpret them
The Result
Time saved: 60-70%
Judgment
retained: 100%
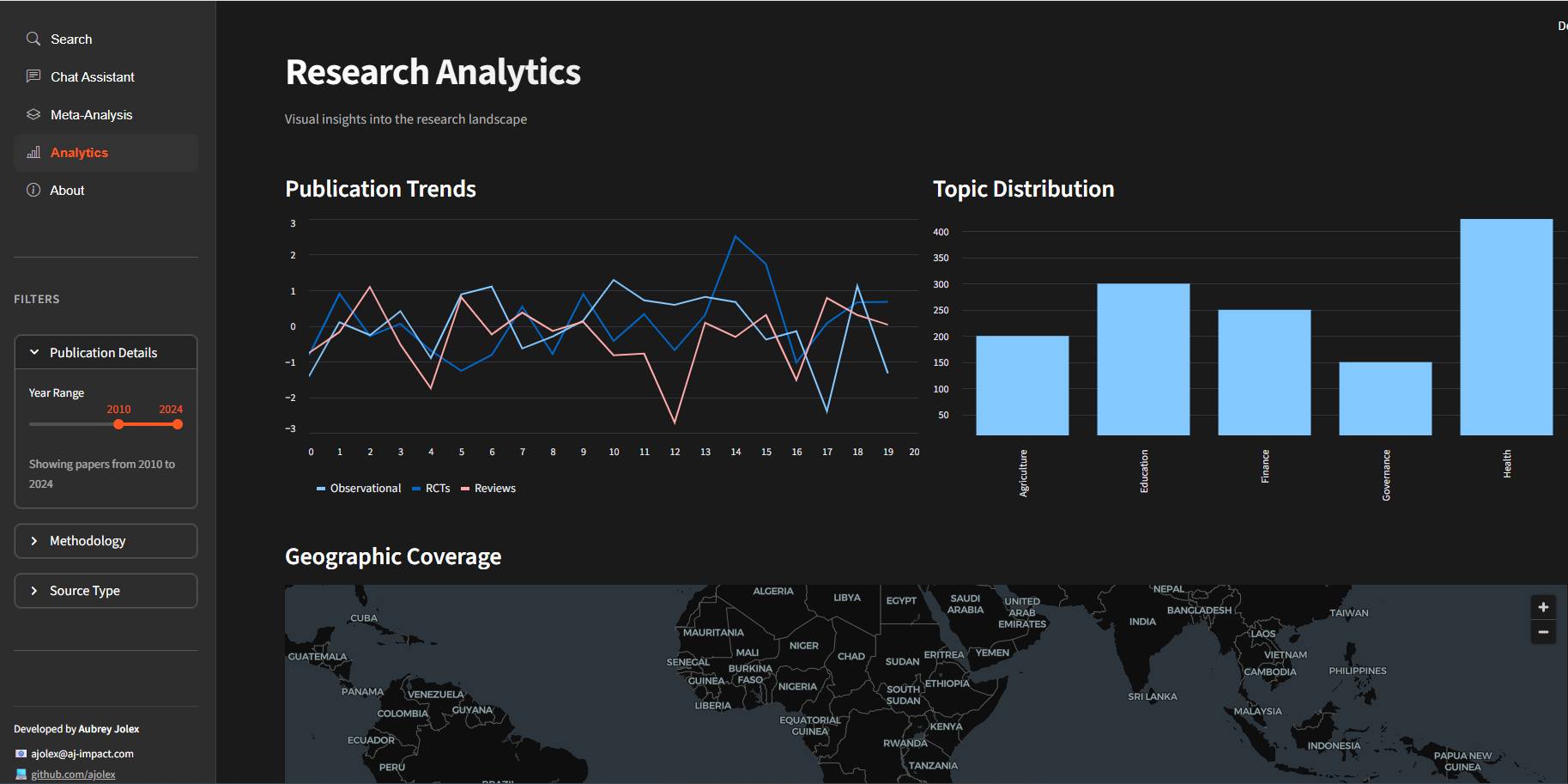
Balancing AI automation
with human judgment.
The Bigger Picture
In development economics, rigor matters. We’re informing policy that affects millions of lives. We can’t afford careless research. But we also can’t afford to waste half our research cycle on logistics.
DERA embodies a principle I believe deeply: smart tools make smarter humans. It
democratizes capabilities once available only to researchers at well-resourced institutions with dedicated research librarians and meta-analysis specialists.
The skepticism about AI in research? It’s not going away—and it shouldn’t. But the solution isn’t rejection. It’s smart collaboration.
What’s your experience been with AI in your research process? Are you finding the balance between efficiency and rigor?
Ready to Elevate Your Research?
Explore how AJ Impact can support your evaluation needs
View Our Work
See how we apply rigorous impact evaluation methods in the field.
View Projects →
Free Consultation
Need help with survey measurement or evaluation design? Schedule a free consultation.
Book Now →
More Resources
Explore our blog for more guides on impact evaluation, RCT design, and survey methodology.
Read Blog →
About the Author
Aubrey Jolex is the founder of AJ Impact Evaluation Consulting, specializing in rigorous impact evaluation for development programs. With 7+ years of experience with leading research organizations such as IPA, IFPRI and IITA, Aubrey has designed complex survey instruments and managed data collection across multiple countries.